DeepSeek-R1 Meets SIMD Code Porting
1. Introduction
Why did DeepSeek become so Famous?
DeepSeek has gathered significant attention in the AI community due to its innovative approach to reasoning and problem-solving. A key factor behind its popularity is its Thinking Process and Chain of Thought (CoT) capabilities. These features enable the model to decompose complex problems into smaller, manageable steps, mimicking human-like reasoning. This makes DeepSeek particularly effective in tasks requiring logical reasoning, such as mathematical problem-solving and coding.
The model's ability to generate intermediate reasoning steps (CoT) has been a game-changer, primarily because it provides transparency into how the model arrives at its conclusions, addressing the issue of interpretability in large language models (LLMs).
A milestone that sets DeepSeek apart is its approach to large-scale reinforcement learning (RL). The team introduced two groundbreaking models:
- DeepSeek-R1-Zero
- DeepSeek-R1
What makes DeepSeek-R1-Zero particularly interesting is that it was trained using large-scale reinforcement learning without the traditional supervised fine-tuning (SFT) step. This novel approach led to the emergence of powerful reasoning capabilities, though it initially faced challenges with readability and language consistency. To address these limitations while maintaining the strong reasoning performance, the team developed DeepSeek-R1. This improved version incorporates multi-stage training and cold-start data before the reinforcement learning phase, achieving performance levels comparable to OpenAI's models on reasoning tasks.
Beyond its technical prowess, another reason for DeepSeek's popularity is its strong presence in the open-source community. By making its models accessible to the public, DeepSeek has fostered a collaborative environment where developers and researchers can contribute to its growth, share insights, and create their own use-cases.
Chain of Thought (CoT)
Chain of Thought is a very simple, yet effective prompt engineering technique. The fundamental principle is straightforward: by instructing the model to "think" aloud, it reveals its complete reasoning process step by step. As a result, if the model makes any mistakes, the user can easily identify where the reasoning went astray and adjust the prompt to correct the error. Rather than treating the model as a black box that produces answers seemingly out of nowhere, Chain of Thought transforms it into a transparent reasoning "partner". For a comprehensive example of CoT, you can refer to DeepSeek's paper.
Reinforcement Learning
Traditionally, AI models are trained by showing them tons of labeled examples (supervised fine-tuning). But DeepSeek took a different path. Instead of guiding the model with pre-labeled data, they used reinforcement learning, which is more like teaching an AI through trial and error. In their approach, the model learns by attempting tasks, receiving feedback, and gradually improving its performance. This approach allows the model to discover strategies and solve problems more independently, potentially uncovering unique reasoning methods that might be missed in traditional training. The reward system mainly consists of two types of rewards:
- Accuracy rewards: The accuracy reward model evaluates whether the response is correct.
- Format rewards: The format reward model enforces the model to put its thinking process between
<think>...</think>tags. Our team at VectorCamp has also applied the Format Reward technique in order to evaluate the model's responses, ensuring they were properly tagged and concise.
2. Our View on the Models: SIMD Code Porting
As mentioned in our previous blog [2], software optimization using SIMD (Single Instruction, Multiple Data) instructions continues to be a critical and intricate challenge in high-performance computing, especially when porting a project from one architecture to another. To address these challenges, we developed SIMD.info, a comprehensive online knowledge base that serves as a centralized repository for SIMD intrinsics. While SIMD.info was a significant step forward, developers still face substantial difficulties in understanding and implementing SIMD optimizations. Our goal was to make this process even more accessible. We aimed to create a solution that not only catalogs information but also actively assists developers in code porting. This led us to explore an exciting frontier: harnessing the potential of Large Language Models (LLMs) to simplify and accelerate SIMD optimization and code porting between different architectures.
Building on our previous research, this blog evaluates the DeepSeek-R1 models (7b, 8b, 14b, 32b, and 70b) to assess their proficiency in generating SIMD code and porting code between different architectures, such as from SSE4.2 to NEON.
System Prompts
As explained in our previous blog [2], SYSTEM prompts serve as crucial runtime instructions that shape how models process and respond to queries. These prompts are not training or fine-tuning modifications, but rather guidance provided to the model during inference. For our testing, we implemented a hybrid SYSTEM prompts approach that combines both technical knowledge and behavioral guidelines. This approach integrates SIMD knowledge base information while establishing clear expectations for the model's role and response format, ensuring consistent and well-structured outputs. Our previous research demonstrated that this combined method delivers superior results compared to using either purely behavioral guidance or technical data integration alone.
In the testing methodology that follows, we evaluated each model variant in two configurations: a plain version without SYSTEM prompts, and an enhanced version incorporating our hybrid SYSTEM prompts approach. This dual testing allows us to quantify the impact of SYSTEM prompts on model performance and assess their effectiveness across different model sizes and architectures.
Testing Methodology
In order to have a clear comparison with the models that we examined in the previous blog, we used almost the same multi-phase testing strategy to systematically evaluate model performance across different complexity levels.
- Phase 1 - Direct Mapping: Focus on one-to-one mapping of SIMD intrinsics between different architectures. This phase tests the models' ability to translate individual SIMD instructions with high precision. We deliberately selected intrinsics that represent diverse computational patterns, including arithmetic operations, data shuffling, comparison instructions, and bitwise manipulations.
- Phase 2 - Function-Level Translation: Complete function translation between architectures. This phase challenges the models to comprehend entire function contexts, understanding not just the individual instructions but the broader algorithmic intent.
This time, we extended our testing to both CPU and GPU environments to also compare the time performance across different hardware platforms. Our methodology was designed to push the models to their limits, assessing their capability to navigate the complex terrain of cross-architecture SIMD optimization.
3. Graph Results and Performance Analysis
We selected Qwen2.5 models (7b and 14b) for our comparative analysis, mirroring DeepSeek's original comparison strategy which utilized the Qwen2.5:72b-inst model. This approach ensures a consistent and meaningful benchmark across different model architectures.
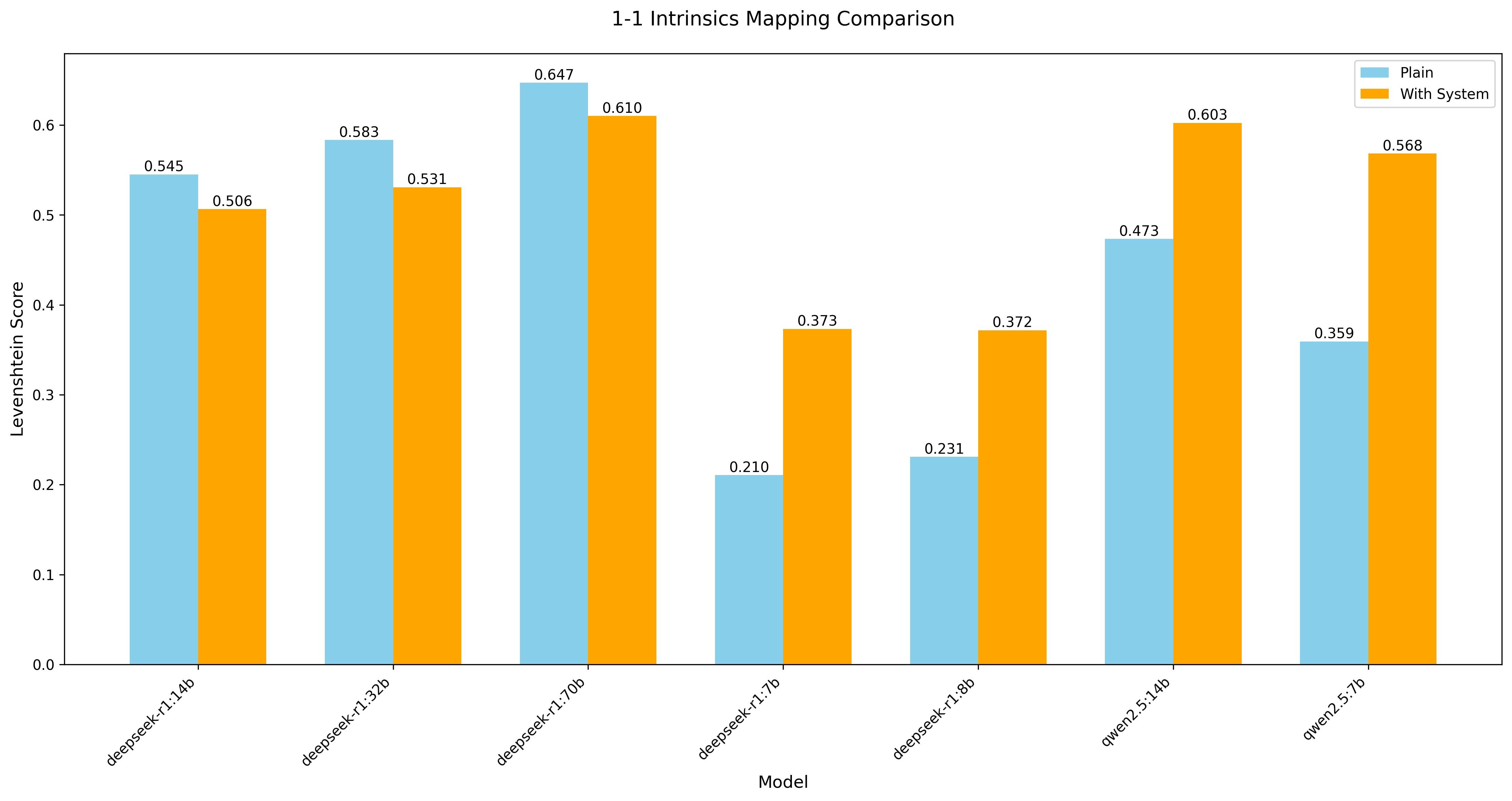
Direct 1-1 Intrinsics Mapping
While Qwen models performed moderately, DeepSeek models not only struggled to deliver accurate translations but also exhibited issues with SYSTEM prompts. An exception to the poor performance of the DeepSeek models was the 70b version that delivered moderately. However, it took the model an astonishing 32755 seconds (~ 9 hours) to complete the task. While Qwen models (and other LLMs) generally benefit from SYSTEM prompts, DeepSeek's SYSTEM prompt handling is fundamentally lacking and inconsistent.
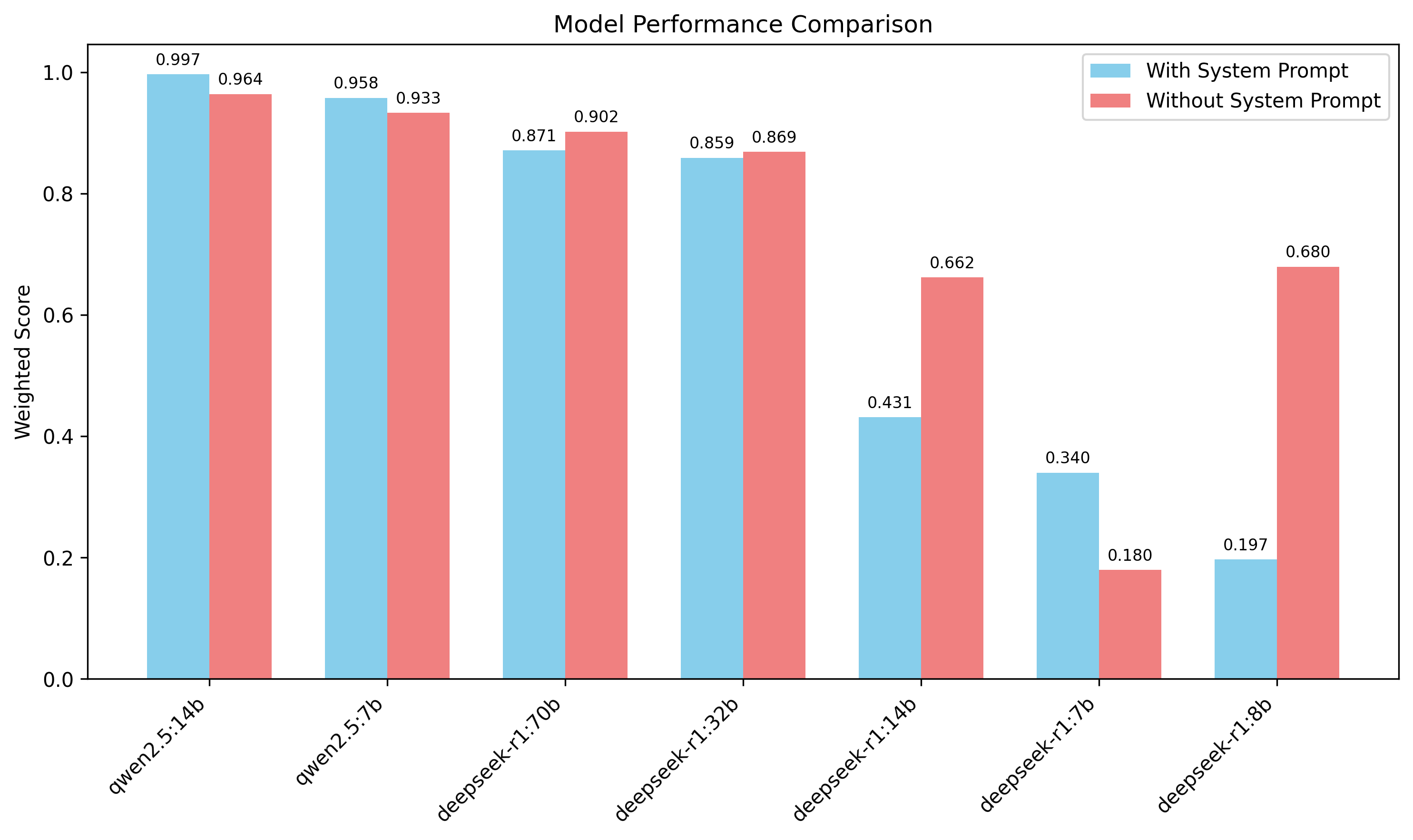
Multifunction Tests
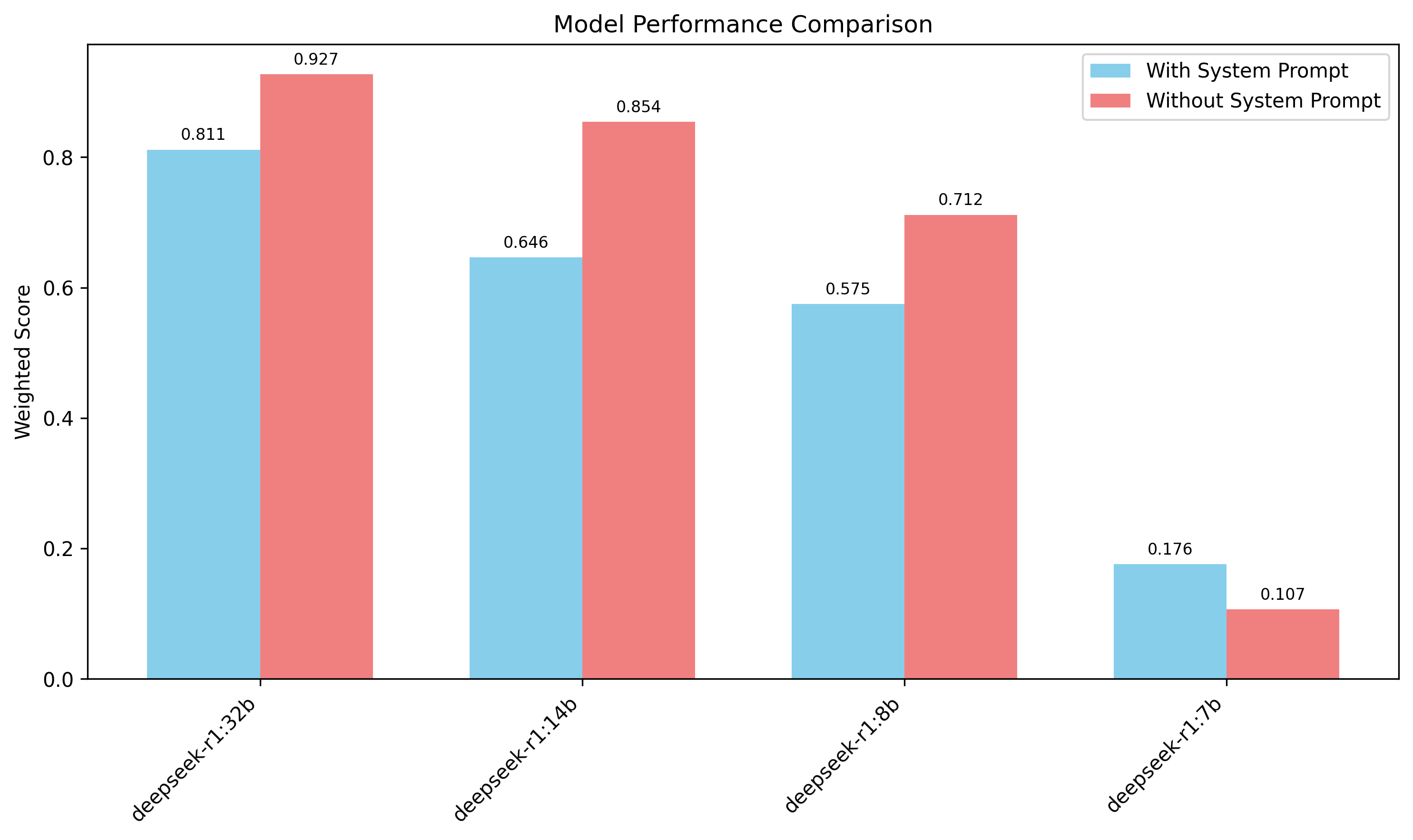
Our multifunction tests reveal intriguing performance dynamics. Qwen2.5:14b achieved an outstanding 0.99 accuracy, with Qwen2.5:7b reaching 0.95 when enhanced by our SYSTEM prompt. In contrast, DeepSeek's 70b and 32b models delivered acceptable but comparatively modest results, particularly when measured against Qwen models with substantially fewer parameters. As mentioned in the direct 1-1 intrinsics mapping test, the effectiveness of SYSTEM prompting varied significantly across models: DeepSeek's 7b model demonstrated approximately 2x improvement, while other models showed minimal to no responsiveness to it. The DeepSeek 7b version remains the only model where SYSTEM prompts consistently provide meaningful improvement.
This inconsistent behavior in DeepSeek's SYSTEM prompt handling is further illustrated in our subsequent graph, which provides more detailed insights into this phenomenon.
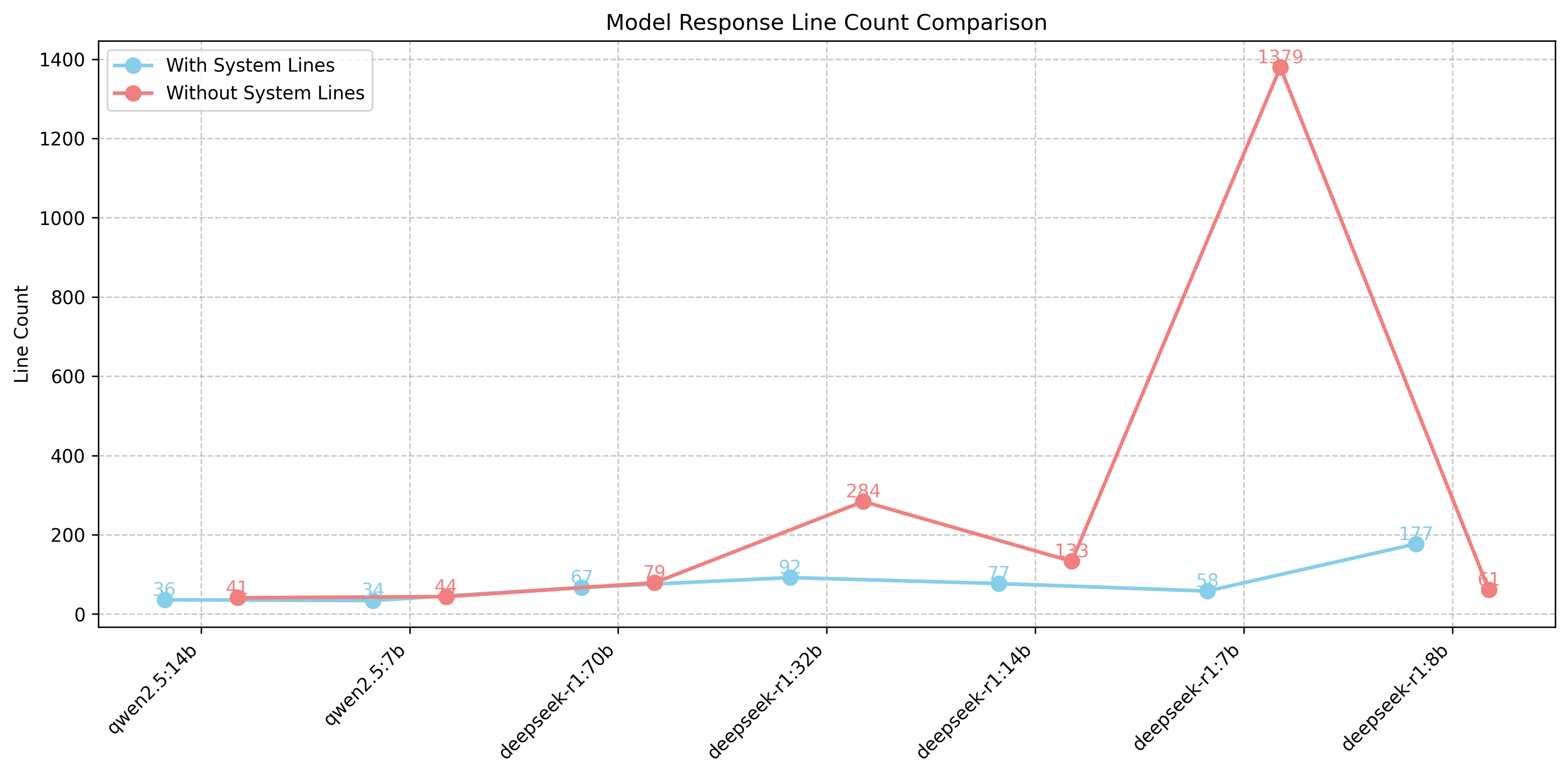
Output Verbosity (line count)
Another key observation in our testing was that DeepSeek models tend to produce excessively verbose outputs. While the <think>...</think> tags successfully encapsulate the model's reasoning process, as intended by the format rewarding mechanism during training, we found that the models also generate an excessive number of additional comments. These unnecessary comments dilute the usefulness of the output, making it more difficult for developers to extract relevant information efficiently. This verbosity issue significantly impacts response times, increasing inference latency.
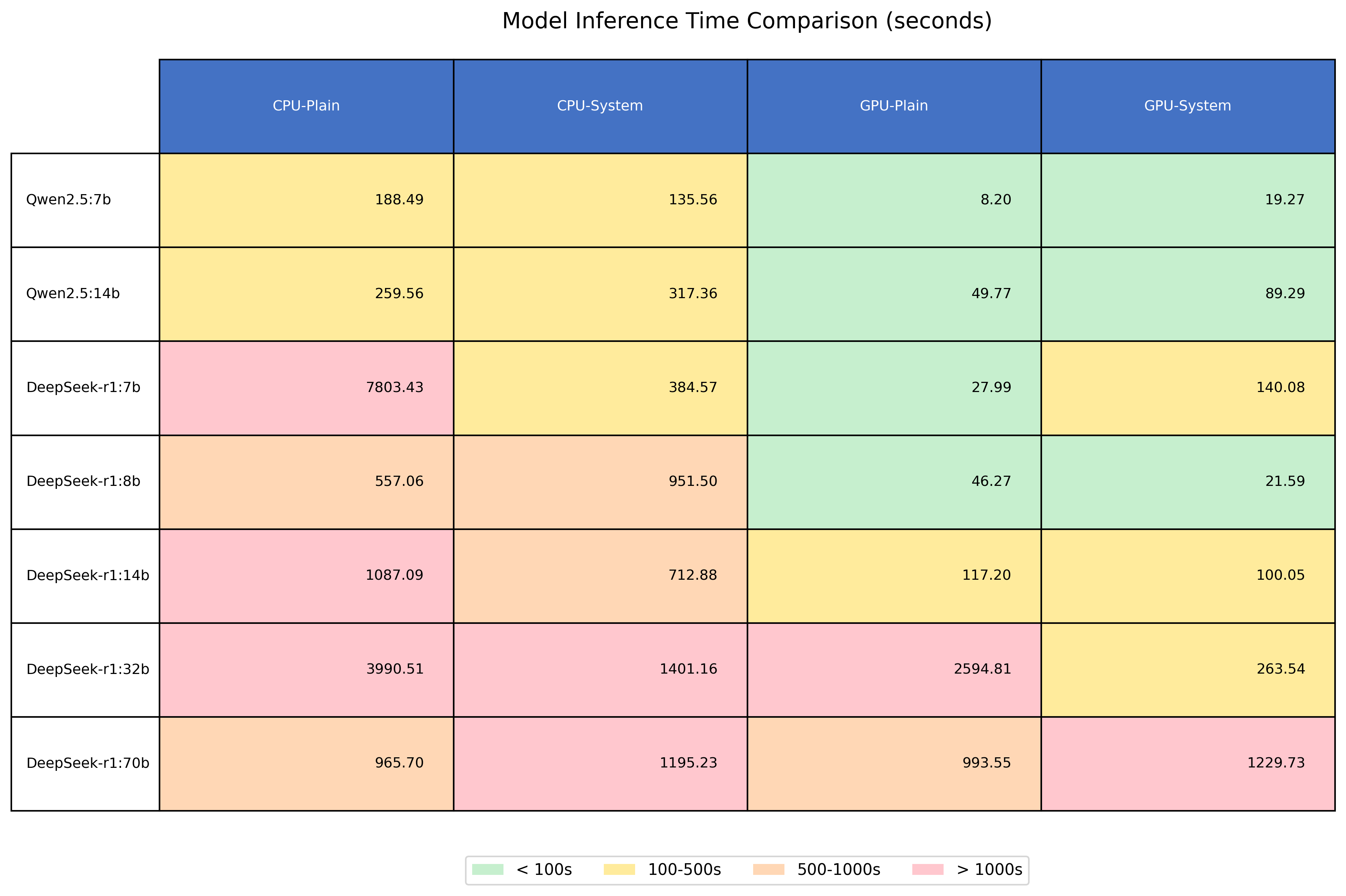
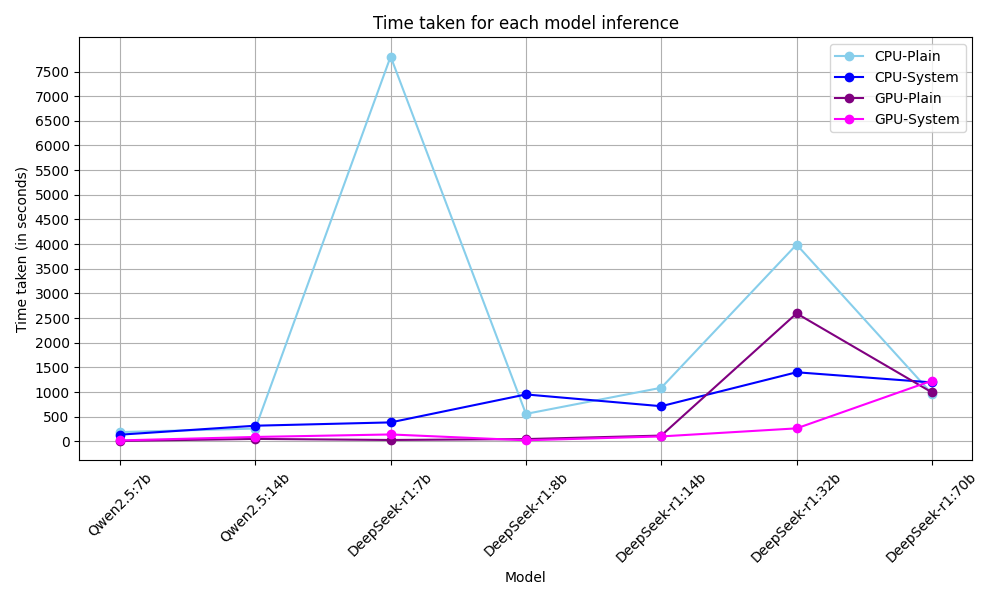
CPU and GPU Timing Comparisons
Our timing tests revealed that DeepSeek models take too much time for inference, likely due to their extensive thinking process. For instance, the DeepSeek-R1:7b model took 7803 seconds to complete inference and generated 1379 lines of output, as discussed in the "Output Verbosity" section. The GPU tests were conducted using an NVIDIA GeForce RTX 4060. Although this is not a high-end GPU card, it did provide significant speedups, results should be even better using a more powerful consumer or server GPU card, specialized for AI calculations. While GPU timings are better than CPU, DeepSeek models remain significantly slower than Qwen models.
As shown in the table, Qwen models completed inference much faster. Additionally, for the 70B DeepSeek models, inference times on CPU and GPU were nearly identical since the model does not fit into the VRAM of our GPU. This highlights the inefficiency of using larger models when smaller models such as Qwen-7B or Qwen-14B can fit within the same GPU memory and deliver competitive performance, making them a far more cost-effective choice.
4. Conclusion
While DeepSeek's reinforcement learning approach has led to strong reasoning capabilities, the models exhibit critical inefficiencies in SYSTEM prompt handling, output verbosity, and inference time. Qwen models, despite having fewer parameters, deliver superior performance in SIMD code porting tasks, making them a more practical choice for our use-case.
For developers seeking efficient LLM-assisted SIMD optimization, DeepSeek's models ultimately do not provide enough value to justify their higher resource costs. The excessive inference times, bloated outputs, and lack of responsiveness to SYSTEM prompts make them inefficient for practical workloads. Given that smaller, more optimized models like Qwen-7B and Qwen-14B can achieve comparable or better results while fitting within standard hardware, DeepSeek models present a costly and suboptimal choice at least in our case.
However, given DeepSeek's unique ability to learn and improve its performance over time, we may attempt to revisit it in the future. This will require a totally different approach than other models, acknowledging the potential for significant advancements in its capabilities.
5. References
[1] DeepSeek-V3 Technical Report [Online]. Accessed: Feb. 4, 2025. (DeepSeek)
[2] Leveraging LLMs for SIMD Optimization [Online]. Accessed: Feb. 4, 2025. (VectorCamp)
[3] DeepSeek-R1 explained to your grandma [Online]. Accessed: Feb. 4, 2025. (Youtube)
[4] DeepSeek-V3 GitHub Repository [Online]. Accessed: Feb. 6, 2025. (DeepSeek)
SIMD Intrinsics Summary
| SIMD Engines: | 6 |
| C Intrinsics: | 10444 |
| NEON: | 4353 |
| AVX2: | 405 |
| AVX512: | 4717 |
| SSE4.2: | 598 |
| VSX: | 192 |
| IBM-Z: | 179 |
Recent Updates
November 2025- LLVM-MCA Metrics: Added latency and throughput data for each intrinsic on a per-CPU basis, plus overall plots for visual analysis.
- IBM-Z SIMD Integration: New SIMD architecture support integrated, including 179 intrinsics.
- Search Engine Migration: Switched from Elasticsearch to Meilisearch — 16× less memory usage, 100× faster responses, and improved search quality.
- Updated Statistics: Scanning expanded to more than 59k repositories, now also including IBM-Z statistics.
Previous Updates
- Intrinsics Organization: Ongoing restructuring of uncategorized intrinsics for improved accessibility.
- Enhanced Filtering: New advanced filters added to the intrinsics tree for more precise results.
- Search Validation: Improved empty search handling with better user feedback.
- Changelog Display: Recent changes now visible to users for better transparency.
- New Blog Post: "Best Practices & API Integration" guide added to the blogs section.
- Dark Theme: Added support for dark theme for improved accessibility and user experience.