Meet SIMD.ai - A Specialist LLM for SIMD Porting
1. Why Bother with SIMD-Specific LLMs ?
Since 2020, we were deep into SIMD work — porting code between architectures like SSE, AVX, NEON, and VSX. The biggest pain? There was no clear mapping between intrinsics. You would spend hours trying to figure out how one instruction translates to another across platforms.
That’s when we thought: what if we trained an LLM to do this?
We tried the big models — ChatGPT, Claude, DeepSeek — but none of them really understood SIMD. They’d generate code that looked right but failed in practice. Wrong functions, missing instructions, broken logic, hallucinations. We even tried finetuning some open models to SIMD Github Projects, but we hit wall.
The problem? Data. These models weren’t trained on real SIMD code. So we built our own dataset — curated, structured, and deep. That’s how simd.info was born: a compact, searchable knowledge base for all major SIMD architectures. With proper data finally in place, we started training our own model in August 2024.
In this post, we’ll share how we built SIMD.ai, the model behind it (simd-ai-2506-1), and our open-source benchmarking suite LLaMeSIMD to prove it actually works.
TL;DR: Generic LLMs don’t get SIMD. So we built one that does.
2. The Setup: How We Got Here
To build SIMD.ai, we needed two main things:
- A platform to host and interact with the model
- The model itself
The Platform
We started by exploring open-source chat interfaces like Open WebUI, LibreChat, and a few others. We chose Open WebUI v0.6.2, since it had the cleanest codebase and fit our needs at the time. Since then, we’ve made heavy modifications to support custom models, fine-grained control, and future expansion.
The Model
As explained in our earlier blogs:
…we tested many open models — Codestral, CodeLlama, Qwen2.5, LLaMA3.3, and others. We even tried methods like SYSTEM Prompting. But most of these models failed at real SIMD porting: misunderstood the task, generated invalid or imaginary intrinsics, messed up instruction prototypes. Even the trillion-parameter proprietary models like ChatGPT had similar issues. They just didn’t “get” low-level SIMD.
Our Pick
Two models really stood out: Codestral and Devstral. Codestral had great performance, but its license wasn’t open enough for our use, so we moved forwards with Devstral which was as good — and had a permissive license we could build on. Even before fine-tuning, it showed strong SIMD understanding. Thanks to simd.info, we had what most models were missing: high-quality, curated data. About 12M tokens — not just code, but full context:
- Function descriptions
- Prototypes
- Assembly mappings
- Architecture-specific notes
This was the real start of training.
3. The Training: DIY, At Scale
Once we had the right model and solid data from simd.info, it was time to fine-tune.
We experimented with several approaches — LoRA (Low-Rank Adaptation), PEFT (Parameter-Efficient Fine-Tuning), and DeepSpeed — to find the right balance between adapting to our dataset and keeping the model's original strengths. The goal was to make the model “understand” low-level SIMD patterns without losing general code sense or safety checks.
Each fine-tuning run was relatively fast — under 24 hours — since the dataset was just 12 million tokens. But don’t let the size fool you: the quality and structure of the data made all the difference.
We trained everything on NVIDIA A100 80GB machines, running many iterations of tuning, testing, and adjusting over the course of about 4–5 months.
The result? SIMD-ai-2506-1 — a 24 billion parameters model that outperforms everything else we tested, both in function-level translation and 1-to-1 intrinsic porting across architectures. It’s fast, accurate, and finally feels like a tool built for actual SIMD developers.
4. Results: How Our Models Stacks Up
As mentioned in the previous section, our model outperforms every other open or proprietary model of any size. We now attach some results that show the actual numbers in 1-to-1 intrinsics porting and in function-level translation. We split these results in architecture pairs.
SSE4.2 to VSX
- 1-to-1 intrinsics translation
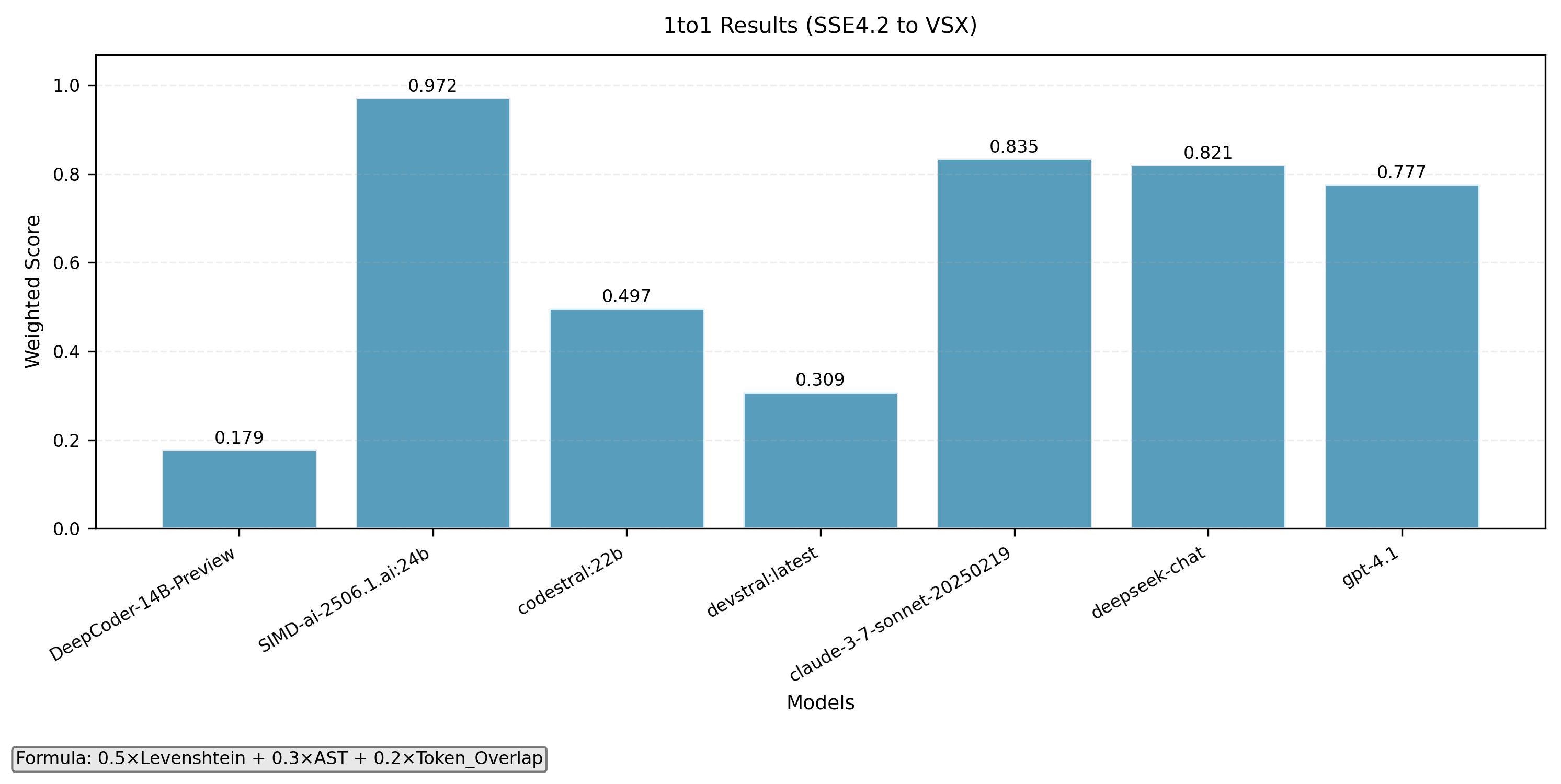
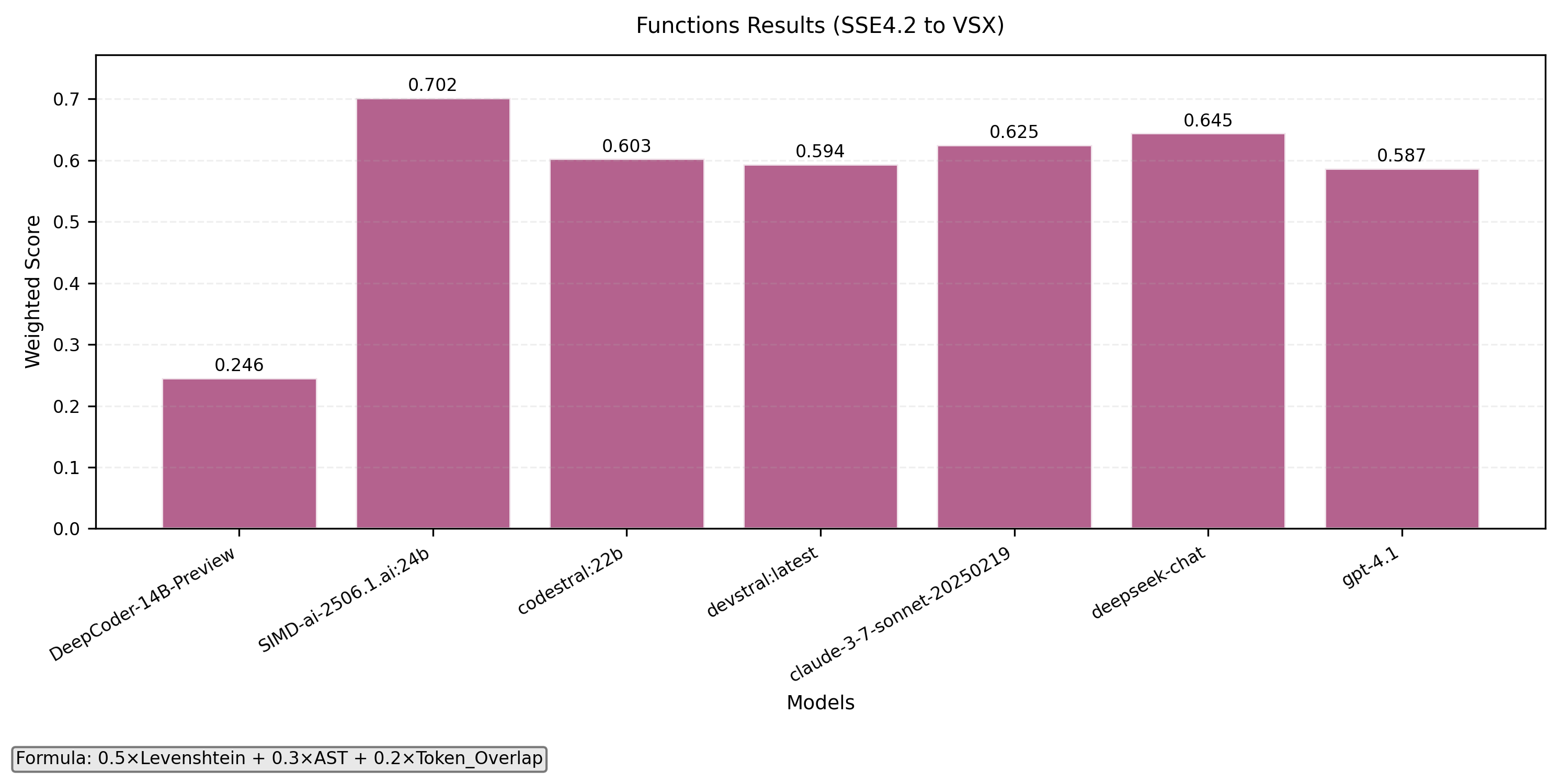
- Function level translation
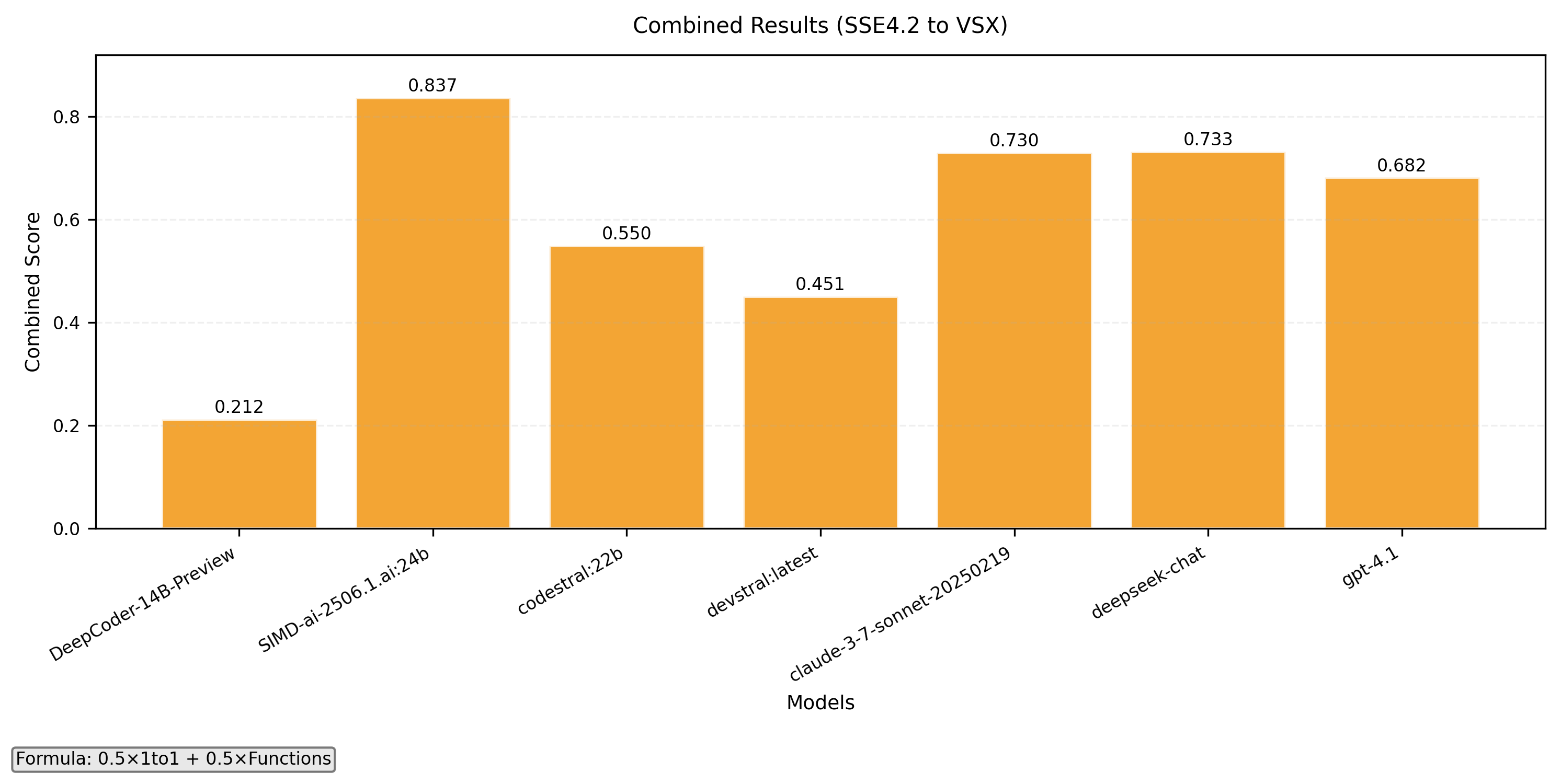
- Combined with formula 0.5x(1-to-1) + 0.5x(Functions)
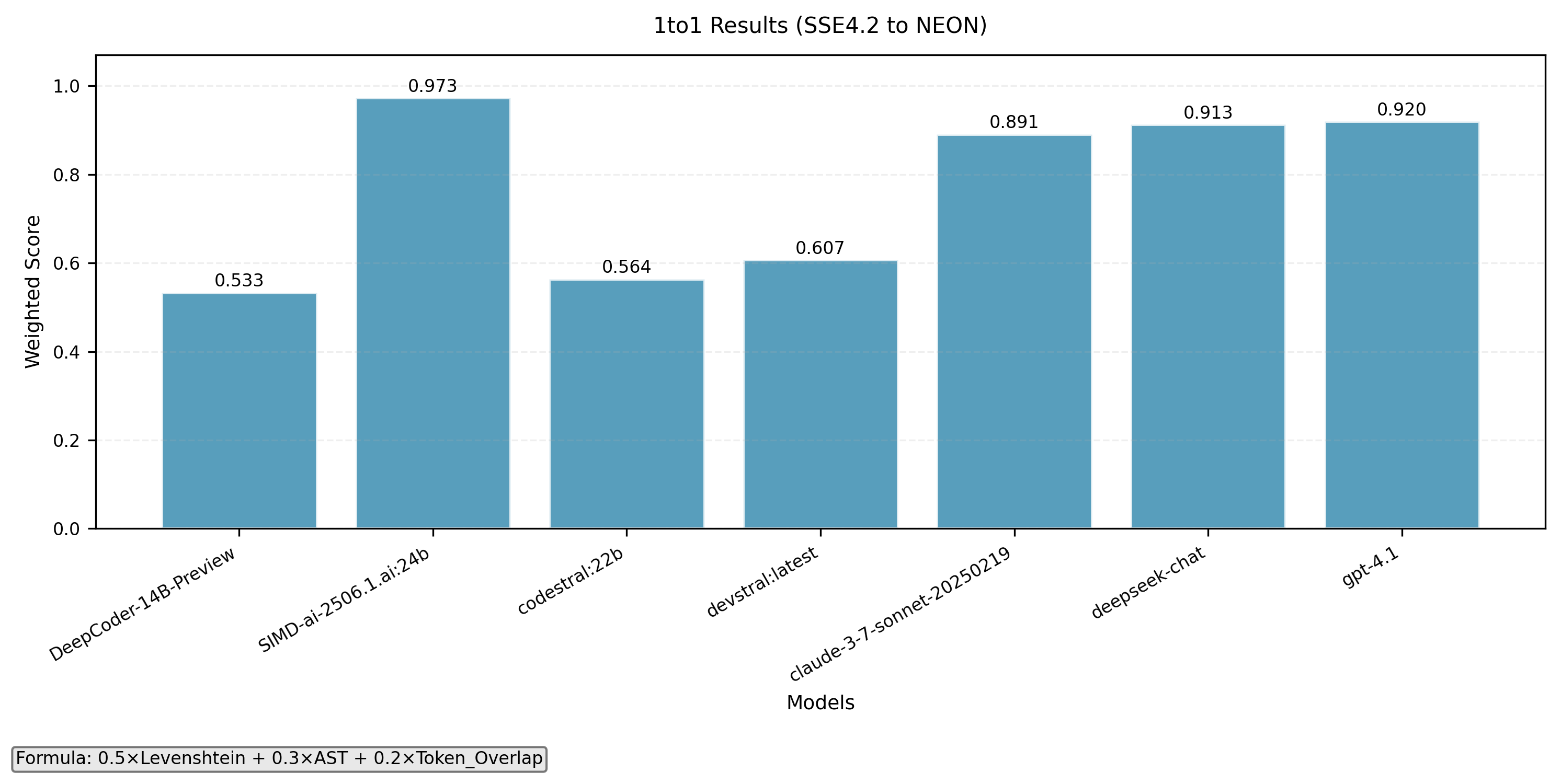
SSE4.2 to NEON
- 1-to-1 intrinsics translation
- Function level translation
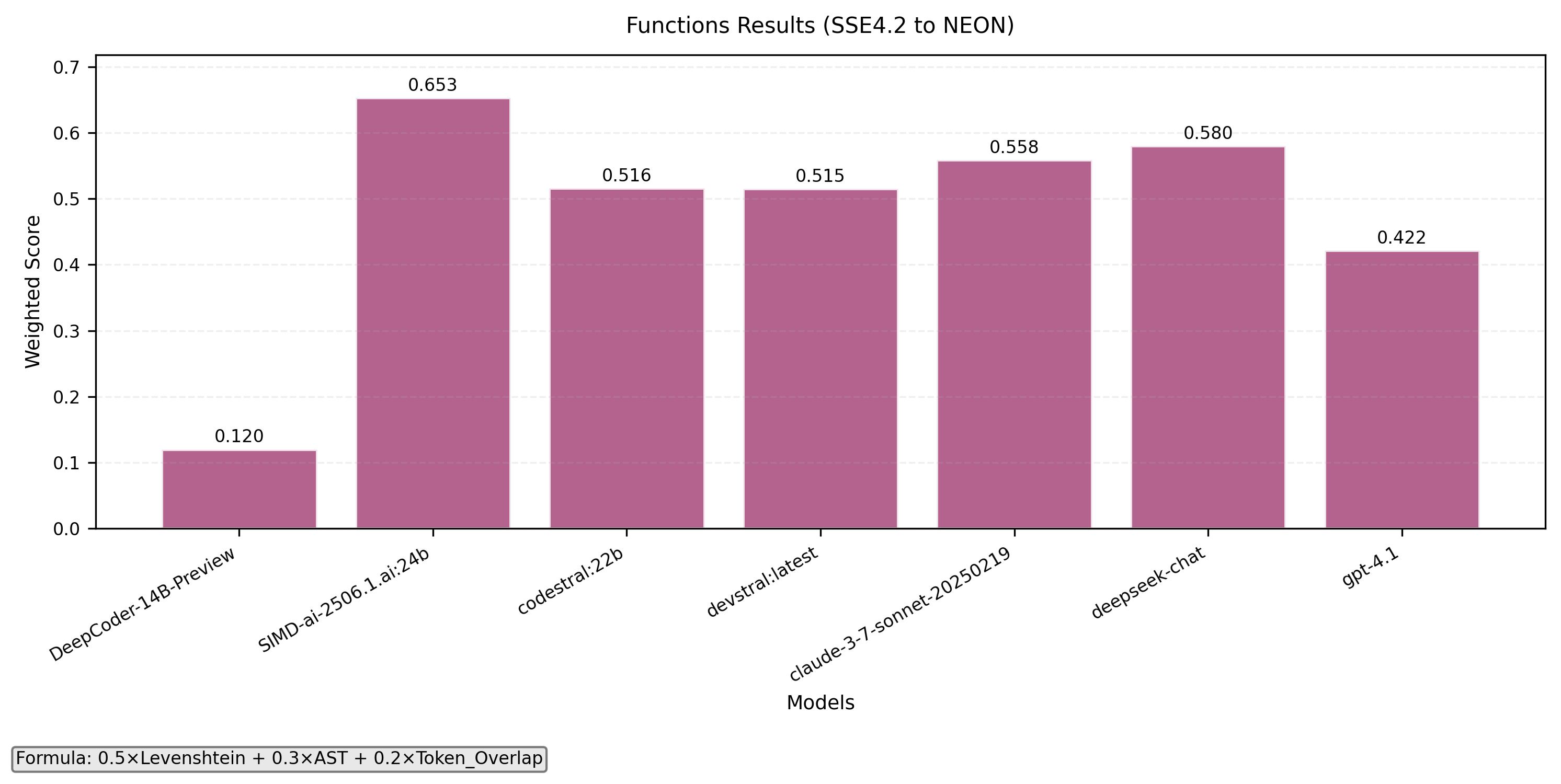
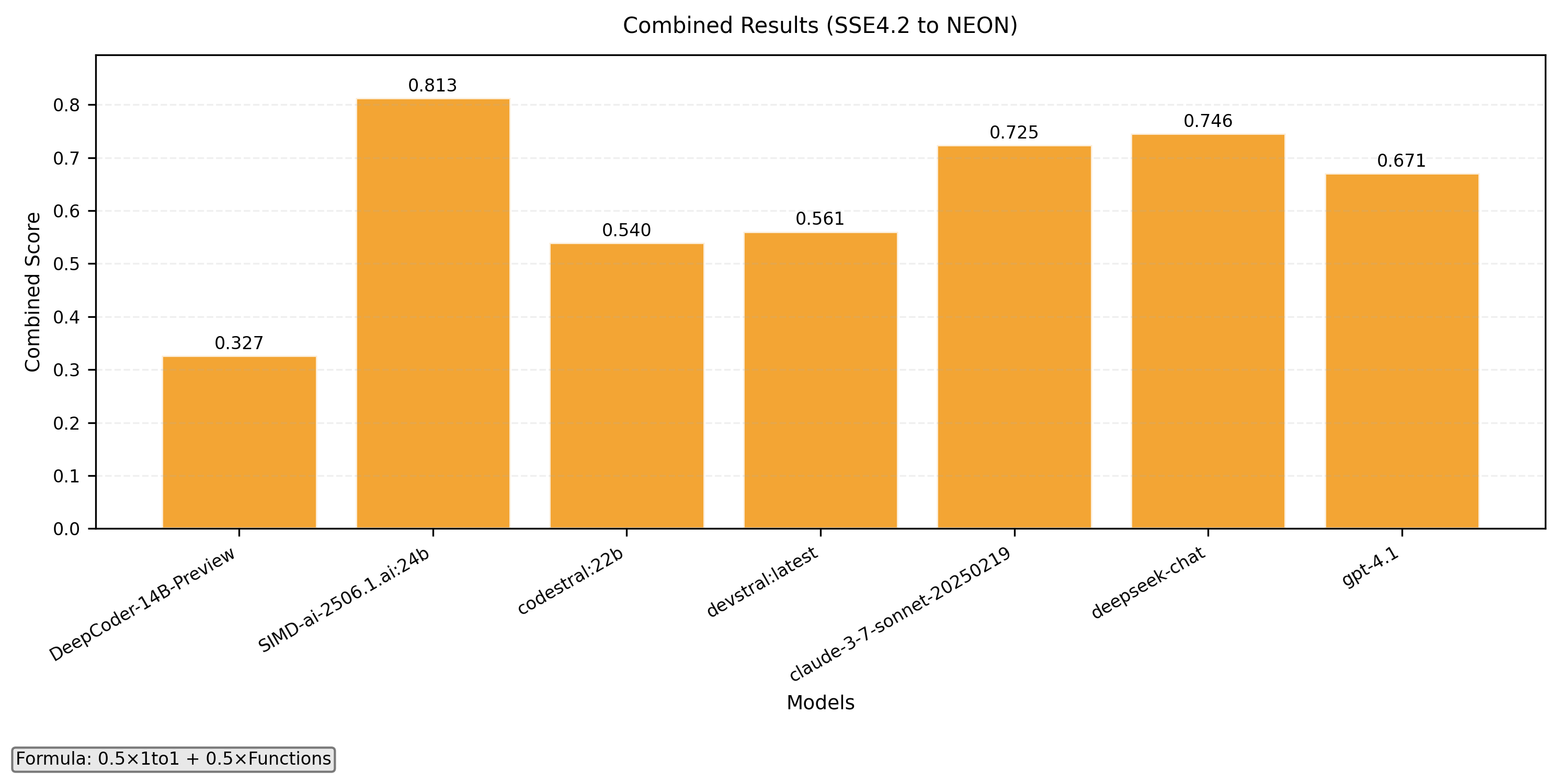
- Combined with formula 0.5x(1-to-1) + 0.5x(Functions)
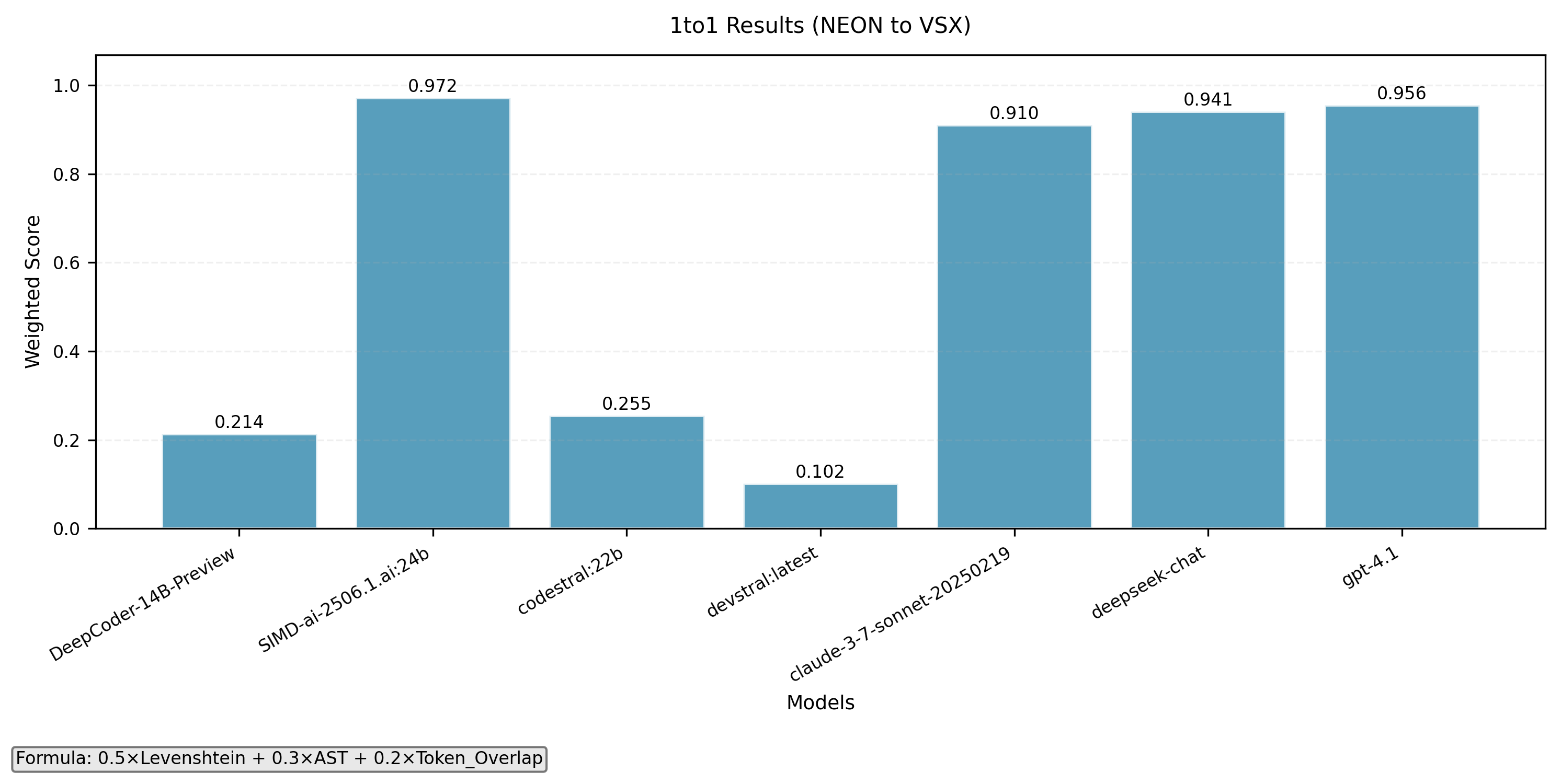
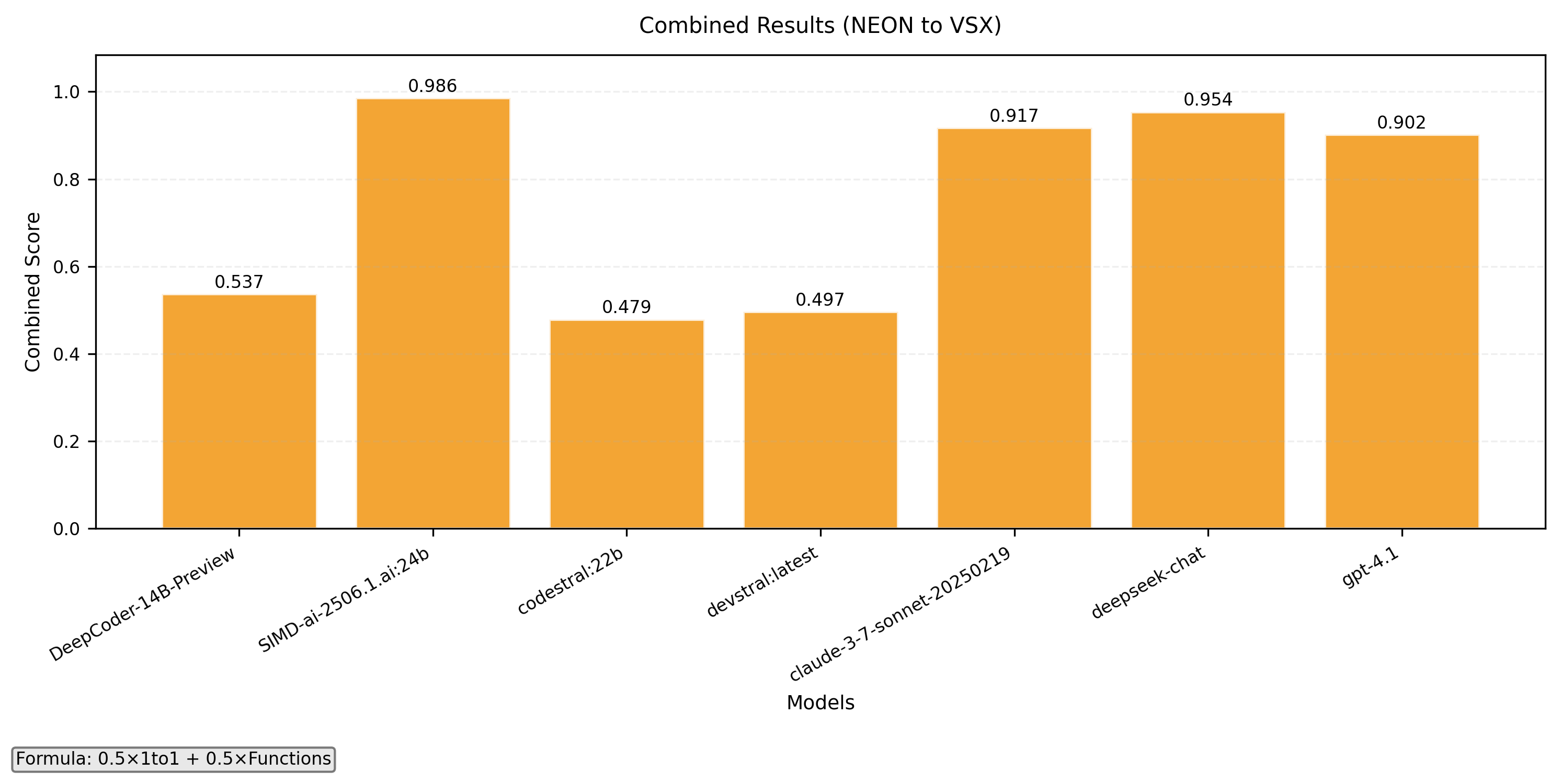
NEON to VSX
- 1-to-1 intrinsics translation
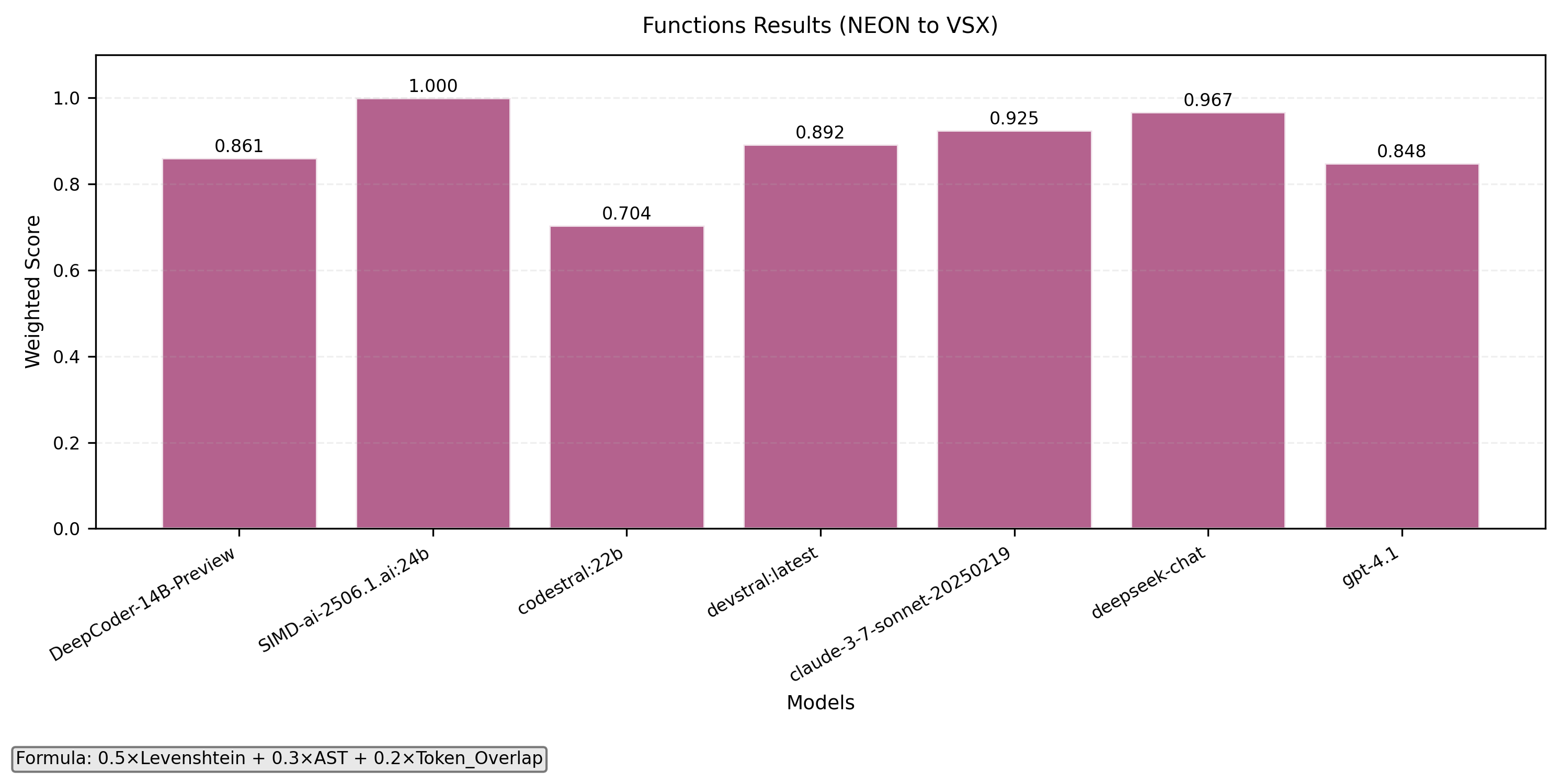
- Function level translation
- Combined with formula 0.5x(1-to-1) + 0.5x(Functions)
5. Meet LLaMeSIMD: The Benchmarking Suite
To back our claims and properly evaluate model performance, we built an open-source benchmarking tool called LLaMeSIMD. It’s the first benchmarking suite focused specifically on testing how well LLMs can translate SIMD code between different CPU architectures. LLaMeSIMD is designed for developers who want to compare models in a reproducible, meaningful way — not just by “vibes,” but by real metrics.
Key Features
- Multi-Architecture Support: SSE4.2, NEON, VSX (more on the way)
- Two Test Modes:
- 1-to-1 intrinsic translation
- Full function translation
- Translation on intrinsics that don't have direct mappings (on the way)
- Robust Metrics: Levenshtein similarity, AST structural similarity, token overlap
- Clear Outputs: Side-by-side comparisons, CSV exports, and clean plots for quick insights
It works with Ollama, Hugging Face, and even proprietary models like GPT-4, Claude and DeepSeek via API.
Setup is straightforward — just follow the README.md in the GitHub repo. AVX2, AVX-512 support and a new compilation-based metric (P@SS-1) are coming soon.
6. Try It Yourself
We’re excited to officially open up SIMD.ai to BETA users! Access is currently invite-only, but the platform is live and ready for testing.
If you'd like early access to SIMD.ai, just drop us an email at simd.ai@vectorcamp.gr — we’d love to hear from you, and we welcome feedback or contributions!
7. Ongoing & Future Development
While SIMD.ai is now live in BETA, we're just getting started.
Here’s a peek at what’s coming next:
- VSCode integration via API (in development)
- IBM-Z vector support (in progress)
- Planned support for more architectures:
Loongson (LSX/LASX), MIPS/MSA, and RISC-V (RVV-1.0)
Thanks for reading — and stay tuned. We're building this for developers, with developers.
SIMD Intrinsics Summary
| SIMD Engines: | 6 |
| C Intrinsics: | 10444 |
| NEON: | 4353 |
| AVX2: | 405 |
| AVX512: | 4717 |
| SSE4.2: | 598 |
| VSX: | 192 |
| IBM-Z: | 179 |
Recent Updates
November 2025- LLVM-MCA Metrics: Added latency and throughput data for each intrinsic on a per-CPU basis, plus overall plots for visual analysis.
- IBM-Z SIMD Integration: New SIMD architecture support integrated, including 179 intrinsics.
- Search Engine Migration: Switched from Elasticsearch to Meilisearch — 16× less memory usage, 100× faster responses, and improved search quality.
- Updated Statistics: Scanning expanded to more than 59k repositories, now also including IBM-Z statistics.
Previous Updates
- Intrinsics Organization: Ongoing restructuring of uncategorized intrinsics for improved accessibility.
- Enhanced Filtering: New advanced filters added to the intrinsics tree for more precise results.
- Search Validation: Improved empty search handling with better user feedback.
- Changelog Display: Recent changes now visible to users for better transparency.
- New Blog Post: "Best Practices & API Integration" guide added to the blogs section.
- Dark Theme: Added support for dark theme for improved accessibility and user experience.