Leveraging LLMs for SIMD Optimization - A Journey from Knowledge Base to AI Assistant
1. Introduction
Problem statement: Need for efficient SIMD optimization across architectures
Software optimization using SIMD (Single Instruction, Multiple Data) instructions remains a critical yet challenging aspect of high-performance computing. While SIMD instructions can dramatically improve performance by processing multiple data elements simultaneously, developers face several significant challenges:
Architecture Diversity: Different processor architectures (x86, ARM, POWER, RISC-V, MIPS, Loongson) implement SIMD instructions differently, making cross-platform optimization complex.
Steep Learning Curve: Each architecture's SIMD instruction set (SSE4.2, AVX2, AVX512, NEON, SVE, SVE2) requires specific knowledge and expertise, creating a significant barrier to entry.
Documentation Complexity: Official documentation for SIMD intrinsics is often scattered across multiple sources, making it time-consuming to find equivalent instructions across architectures.
Constant Evolution: As new processor generations introduce enhanced SIMD capabilities, keeping track of the latest optimizations becomes increasingly challenging.
Overview of SIMD.info knowledge base
To address these challenges, we developed SIMD.info, a comprehensive online knowledge base that serves as a centralized repository for SIMD instruction information. The platform contains:
- A database of over 10,000 intrinsics across multiple architectures
- Detailed documentation including purpose, results, and usage examples
- Cross-reference capabilities for finding equivalent instructions
- Code examples and assembly output
- Architecture-specific information and compatibility details
- Advanced search capabilities (intrinsic/architecture specific, natural language)
- Community features (discussion forum - StackOverflow-like Q&A system)
Why we considered LLMs as a solution
While our knowledge base significantly improved access to SIMD information, we recognized an opportunity to enhance its utility through Large Language Models (LLMs). Our motivation for exploring LLMs included:
Leveraging Structured Data Assets: With over 10,000 well-structured, categorized SIMD intrinsics in our database, we recognized that data is the new currency in the AI era. Our carefully curated knowledge base represented an valuable asset that could be transformed into an intelligent system through LLMs, potentially creating additional value from our existing documentation efforts.
Code Optimization Assistant: Enable developers to input code snippets that need optimization, and receive suggestions for SIMD-based improvements, along with relevant instruction alternatives and implementation strategies.
Cross-Architecture Translation: Automatically identify equivalent SIMD instructions across different architectures.
Context-Aware Assistance: Provide optimization suggestions based on the specific code context and performance requirements.
Knowledge Synthesis: Combine information from multiple intrinsics to suggest optimal implementation strategies.
Vision: AI-Powered SIMD Optimization Ecosystem
Our roadmap for transforming the static SIMD knowledge base into an intelligent optimization system consists of three key initiatives:
- Web Platform Integration
- Direct integration with simd.ai
- Users input functions and specify target architectures
- System provides optimized SIMD translations in real-time
- CI/CD Pipeline Automation
- Automated SIMD optimization within existing development workflows
- Developers provide source code and unit tests
- AI system performs:
- Function translation
- Iterative testing
- Performance optimization
- Best implementation selection
- IDE Integration
- VS Code extension for seamless developer experience
- Select code directly in the editor
- Choose target architecture
- Receive SIMD-optimized translations instantly
These initiatives represent our commitment to making SIMD optimization accessible and efficient for developers at every stage of their development process.
2. Initial Exploration Phase & Data Engineering
LLM Landscape Analysis
Model Categories Evaluated
- Proprietary Models
- GPT-4, GPT-3.5, Claude, PaLM
- High capability, but costly with vendor lock-in
- Open-Source Models
- LLaMA derivatives, Bert, GPT-J, Falcon
- Greater flexibility and control
- Code-Specific Models
- StarCoder, CodeLlama, Codestral
- Optimized for code tasks
Key Technical Factors
- Model Characteristics
- Size range: 3B-405B parameters
- CPU deployment focus: 3-7B models (with an exception for Nemotron-70B)
- Memory and speed trade-offs
- Implementation Concerns
- Licensing (Apache, MIT, proprietary)
- CPU-only deployment requirements
- Usage of the available system's memory
- Quantization options
- Framework selection (starting with Hugging Face)
Implementation Steps
Our implementation began with Hugging Face integration, leveraging StarCoder2-3b and 7b models to establish our baseline workflow. Through this process, we developed effective prompt engineering techniques and established fundamental operational patterns.
Data processing presented unique challenges in converting our YAML-based knowledge into LLM-compatible formats. We optimized context lengths and standardized terminology across different architectures while preserving technical accuracy.
For CPU optimization, we experimented with 8-bit & 16-bit quantization (when available), but found significant degradation in response quality, particularly for coding tasks which is our main concern. We ultimately maintained FP32 precision to ensure accuracy, while implementing efficient batch processing and threading strategies.
Data Engineering
Our SIMD knowledge base contains over 10,000 intrinsics across multiple processor architectures, structured in YAML format with comprehensive technical details for each instruction. We transformed this data into LLM-friendly formats using a source-target approach, where each example pair contained structured information about architectures and instruction mappings.
Key challenges in this process included managing the large volume of technical data, maintaining accuracy across different architectures, and balancing detailed context with model limitations. We developed automated Python scripts for data processing and evaluation to address these challenges effectively.
3. Learning Through Failure and Model Selection
Our first ambitious attempt at fine-tuning StarCoder2-7B resulted in a significant setback. The training process was projected to take 22 days and failed after 10 days, revealing our overconfidence in a single model and underestimation of CPU constraints. This failure prompted a more methodical approach to model selection.
We developed a systematic evaluation framework focusing mainly on models within the 3-7B parameter range, with strong CPU inference support and open-source licensing. Our testing methodology included:
- Reference Testing
- Curated set of equivalent SIMD functions across architectures
- Automated testing pipeline
- Structured response analysis criteria
- Response Analysis
- Format: Code block presentation (XML-style) and documentation style
- Structure: Consistent organization and clear sections
- Style Categories:
- Comprehensive analysts: Detailed but verbose (models like Reflection & NeuralChat)
- Direct implementers: Concise, code-focused (models like Codestral & CodeLlama)
- Academic theorists: Theory-heavy approaches (earlier versions models)
This structured approach helped identify models that could provide accurate, well-formatted, and practical optimization suggestions, forming the foundation for our subsequent development phases.
4. Refinement and Evaluation
Integration with Ollama
Ollama is a Local AI Model Management tool that grants you full control to download, update, and delete models easily on your system. Our transition to it marked a significant improvement in model interaction and testing efficiency. Ollama provided two key interfaces:
- CLI: Enabled rapid prototyping and testing through simple terminal commands
- Python API: Facilitated automated testing and systematic evaluation
The platform's efficient model management system significantly reduced friction in our testing process, allowing quick iteration through different configurations.
SYSTEM Prompts Implementation
The discovery of SYSTEM prompts proved pivotal for optimization. Our experimentation revealed three approaches:
- Behavioral Guidance: Focused on role and response format
- Technical Data: Direct SIMD knowledge base integration
- Hybrid Approach: Combined technical knowledge with behavioral guidelines (most effective)
The hybrid approach proved most successful, maintaining our source-target JSON structure while adding clear interaction parameters.
Evaluation Framework
We placed particular emphasis on measuring the quality of code-related responses, as this was crucial for our SIMD optimization and cross-architecture translation goals. While our research uncovered various established metrics like BLEU score and CodeBLEU, we decided to develop a custom suite of metrics that specifically addressed our unique requirements for SIMD instruction comparison and code similarity.
- Core Metrics
- Levenshtein Similarity for syntactic accuracy
- Abstract Syntax Tree (AST) Similarity for structural correctness
- Token Overlap Similarity for functional completeness
- Response Line Count for output efficiency
- Selection Process
- Initial pool of 30 models reduced to 4 final selections
- Over 20 comprehensive test runs per model
- Focus on consistent high performance across metrics
- Emphasis on reliable output formatting and resource efficiency
This metric suite provided a balanced view of model performance, considering both syntactic accuracy and functional correctness while remaining sensitive to the specific requirements of SIMD optimization tasks.
Testing Methodology
Building upon our initial response analysis, we developed a more structured and comprehensive approach to model evaluation. This refined methodology leveraged our experience with Ollama modelfiles and SYSTEM prompts, implementing a multi-phase testing strategy to systematically evaluate model performance across different complexity levels.
Phase 1: Direct Mapping
- Focus on one-to-one mapping of SIMD intrinsics
- Sample size: 100 selected intrinsics that have 1-1 direct mapping from one architecture to another
- Multiple source-target architecture pairs (SSE4.2 -> NEON, SSE4.2 -> VSX, NEON -> VSX)
- Clean, focused code output priority
For example, we prompted the LLMs to translate specific SIMD intrinsics between architectures, providing the source intrinsic and target architecture. Each prompt was enhanced with systematic context through the SYSTEM prompt, which included architecture-specific documentation from our knowledge-base.
Sample prompt structure:
input:
simd: SSE4.2
intrinsic: _mm_mul_pd
output:
simd: NEON
intrinsic: vmul_f64
Phase 2: Function-Level Translation
- Complete function translation between architectures
- Validation of intrinsic translation accuracy
- Structure maintenance verification
- Type conversion accuracy checks
For our function-level testing, we selected a diverse set of SIMD functions with escalating complexity levels. While the code below is shown in ARM NEON syntax, we maintained equivalent implementations across all target architectures (SSE4.2, VSX) in our test suite. This approach allowed us to validate translations between any architecture pair while maintaining functional equivalence.
// Basic Level: Performs a series of NEON vector operations
float32x4_t perform_calculations_neon(float32x4_t a, float32x4_t b) {
uint32x4_t cmp_result = vcgtq_f32(a, b);
float32x4_t add_result = vaddq_f32(a, b);
float32x4_t mul_result = vmulq_f32(add_result, b);
float32x4_t sqrt_result = vsqrtq_f32(mul_result);
return sqrt_result;
}
// Intermediate Level: Multiply and add arrays with scalar
void mul_add_arrays(float* a, float* b, float* result, float scalar) {
float32x4_t vec_a = vld1q_f32(a);
float32x4_t vec_b = vld1q_f32(b);
float32x4_t vec_res = vmulq_f32(vec_a, vec_b);
float32x4_t vec_scalar = vdupq_n_f32(scalar);
vec_res = vaddq_f32(vec_res, vec_scalar);
vst1q_f32(result, vec_res);
}
// Advanced Level: Dot product with scaling operation
void dot_product_and_scale_neon(float *a, float *b, float *c, float *result) {
float32x4_t va = vld1q_f32(a);
float32x4_t vb = vld1q_f32(b);
float32x4_t vc = vld1q_f32(c);
float32x4_t mul = vmulq_f32(va, vb);
float32x2_t sum = vpadd_f32(vget_low_f32(mul), vget_high_f32(mul));
sum = vpadd_f32(sum, sum);
float32x4_t scale_factor = vdupq_lane_f32(sum, 0);
float32x4_t scaled_result = vmulq_f32(vc, scale_factor);
vst1q_f32(result, scaled_result);
}
Each function tests different aspects of SIMD optimization, from basic arithmetic operations to more complex algorithms involving horizontal operations and data reorganization.
While not yet implemented, we have designed Phase 3 to test more complex scenarios. We deliberately postponed phase 3 until we could establish strong baseline performance in the more straightforward translation tasks
Results Analysis
Our analysis revealed distinct performance patterns across tested models. The integration of our knowledge base via SYSTEM prompts significantly improved translation accuracy and consistency. Here's a representative sample that show the difference between the unmodified models and the same models using SYSTEM prompts:
Code Snippets Results:
Model
Modelfile with custom SYSTEM directive
Unmodified Model
Model
Levenshtein
AST
Token Overlap
Weighted Score
Line Count
Levenshtein
AST
Token Overlap
Weighted Score
Line Count
neural-chat
0.9702
0.9091
0.8947
0.9368
8
0.7345
0.6071
0.6000
0.6694
8
codestral
0.9281
0.9167
0.9048
0.9200
16
0.3708
0.3385
0.3016
0.3472
21
nemotron
0.7910
0.8976
0.8043
0.8257
13
0.6728
0.4315
0.3116
0.3872
15
solar
0.9459
0.8800
0.8636
0.9097
9
0.7343
0.5405
0.5000
0.6293
9
codellama
0.8900
0.8750
0.8571
0.8789
11
0.2143
0.2211
0.1868
0.2108
25
codegemma
0.9435
0.7391
0.7000
0.8335
18
0.9474
0.7391
0.7000
0.8354
24
llama3.2
0.8970
0.7391
0.7000
0.8102
23
0.2987
0.2424
0.1875
0.2596
32
reflection
0.7845
0.8182
0.7895
0.7956
76
0.6348
0.5556
0.5152
0.5871
79
llama3.1:8b
0.8235
0.6429
0.5600
0.7166
28
0.3851
0.2857
0.1667
0.3116
45
qwen2.5:14b
0.7861
0.6562
0.6207
0.7141
21
0.5983
0.3878
0.3478
0.4851
35
qwen2.5-coder:7b
0.7598
0.6250
0.5667
0.6807
22
0.2996
0.3134
0.2812
0.3001
47
phi3:medium
0.7172
0.6400
0.5217
0.6549
17
0.6051
0.4706
0.4194
0.5276
10
codellama:70b
0.5928
0.5676
0.5000
0.5667
18
0.7174
0.7333
0.7037
0.7194
17
qwen2.5:7b
0.8602
0.9655
0.9600
0.9117
9
0.7942
0.8750
0.8621
0.8320
26
gemma2
0.5856
0.3953
0.3250
0.4764
29
0.7955
0.6452
0.6071
0.7127
29
llama3.1
0.5585
0.3953
0.2895
0.4557
26
0.1973
0.1635
0.1200
0.1717
52
mistral
0.5945
0.3182
0.2308
0.4388
16
0.8033
0.6207
0.6522
0.7183
21
starcoder:7b
0.4263
0.4737
0.4000
0.4352
22
0.5988
0.7083
0.6842
0.6487
35
starling-lm
0.4983
0.3542
0.3111
0.4176
32
0.5762
0.4500
0.4167
0.5065
37
gemma2:2b
0.3550
0.2857
0.2222
0.3077
50
0.4172
0.3478
0.2791
0.3687
30
starcoder2:7b
0.1884
0.2353
0.1705
0.1989
34
0.0101
0.0000
0.0000
0.0051
3
phi3
0.1396
0.0724
0.0541
0.1023
17
0.1081
0.0609
0.0359
0.0795
72
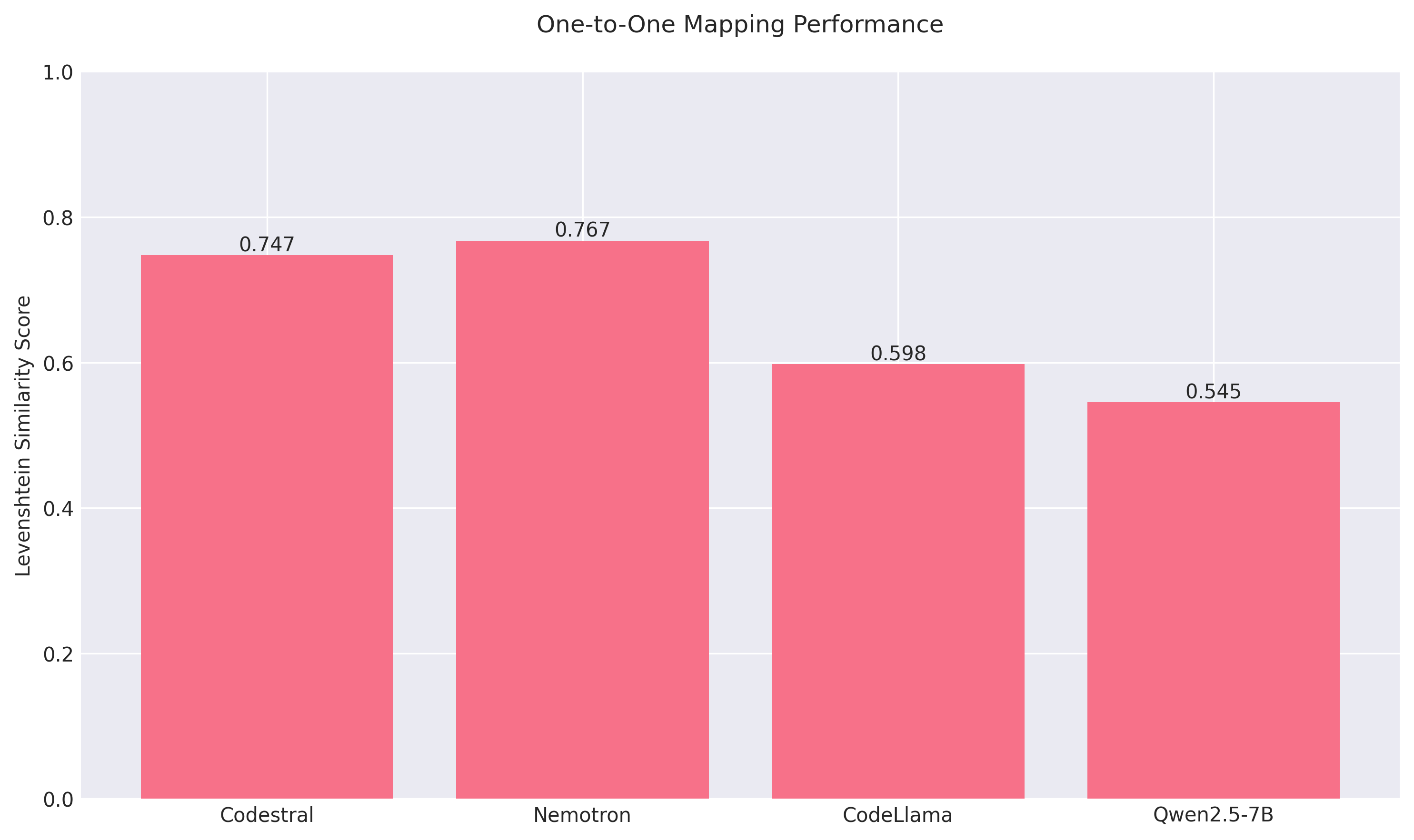
1-1 Mapping Results:
Model
Levenshtein
codestral:latest
0.7473
nemotron:latest
0.7674
codellama:latest
0.5141
qwen2.5-coder:7b
0.4559
...
Through this rigorous process, we narrowed our selection to 4 models. We deliberately included models that might not have topped every metric but have demonstrated:
- Consistently high metric scores
- Reliable performance across different test scenarios
- Efficient resource utilization
- Clean Response formatting (code inside XML tags & not being so verbose)
For example, while Nemotron showed slightly lower accuracy in function translations, it excelled in direct mapping tasks.
These models showed particular strength in all key selection criteria & becamse our final choices (for now at least). They also demonstrated complementary strengths, allowing us to potentially leverage different models for different architectures translations.
5. Current Implementation
Selected Models
After the extensive evaluation, four models demonstrated superior performance for SIMD optimization:
Performance Analysis
Our extensive testing revealed clear patterns in model performance across different tasks. In one-to-one SIMD intrinsic mapping, Codestral and Nemotron consistently emerged as the top performers, maintaining Levenshtein similarity scores above 0.74. For complete function translations, all four selected models (Codestral, Nemotron, CodeLlama, and Qwen2.5-7B) consistently ranked in the top 4-5 positions, though their relative ordering showed some variability across different test cases. Notably, Qwen2.5-7B often emerged as the number one model in handling function translations, indicating its particular strength in this area. To visualize these patterns, we've created two key visualizations:
- A bar chart showing the consistent superior performance of Codestral and Nemotron in one-to-one mapping tasks
- A line graph demonstrating the varying but consistently strong performance of all four models across multiple function translation tests
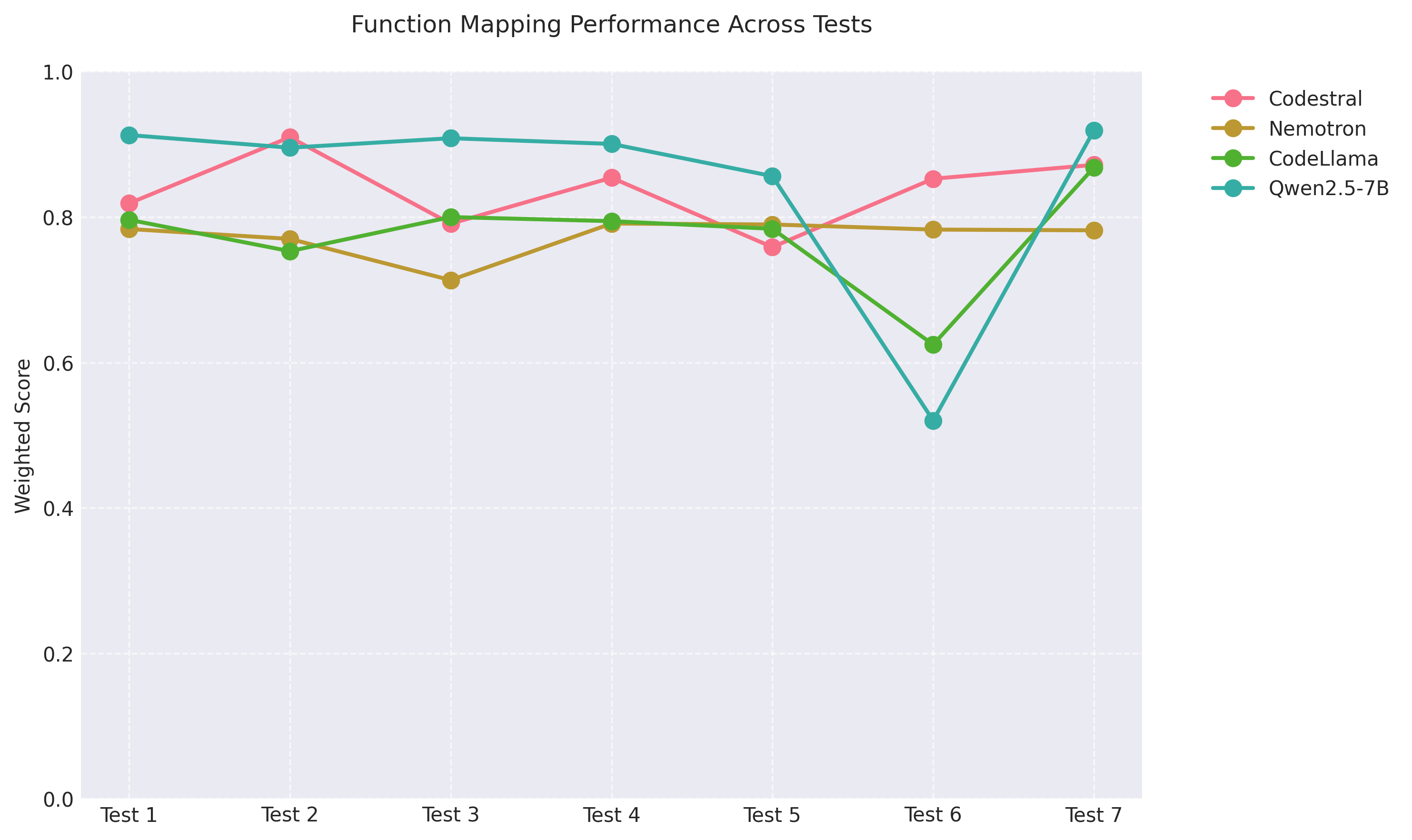
A notable observation from the performance graph is test case 6, where all models except Codestral show a significant performance drop. This particular test incorporated the most challenging one-to-one SIMD mappings available in our knowledge-base.
Next Steps
With these promising results, we are proceeding to the model fine-tuning phase to further optimize performance. Our next steps include:
- Leveraging GPU acceleration for the fine-tuning process to enhance training efficiency
- Publishing comprehensive benchmarks and performance metrics in our follow-up analysis
Stay tuned for our next blog where we'll share detailed insights from the fine-tuning experiments and their impact on model performance.
Event about "Software Optimization: Using SIMD on modern architectures"
We also organized an event in collaboration with the ACM Student Chapter at the Computer Engineering & Informatics Department (CEID) of the University of Patras, Greece. The event was sponsored by Arm. To learn more about the event, check out our LinkedIn post.
You can download the presentation here.
SIMD Intrinsics Summary
| SIMD Engines: | 6 |
| C Intrinsics: | 10444 |
| NEON: | 4353 |
| AVX2: | 405 |
| AVX512: | 4717 |
| SSE4.2: | 598 |
| VSX: | 192 |
| IBM-Z: | 179 |
Recent Updates
November 2025- LLVM-MCA Metrics: Added latency and throughput data for each intrinsic on a per-CPU basis, plus overall plots for visual analysis.
- IBM-Z SIMD Integration: New SIMD architecture support integrated, including 179 intrinsics.
- Search Engine Migration: Switched from Elasticsearch to Meilisearch — 16× less memory usage, 100× faster responses, and improved search quality.
- Updated Statistics: Scanning expanded to more than 59k repositories, now also including IBM-Z statistics.
Previous Updates
- Intrinsics Organization: Ongoing restructuring of uncategorized intrinsics for improved accessibility.
- Enhanced Filtering: New advanced filters added to the intrinsics tree for more precise results.
- Search Validation: Improved empty search handling with better user feedback.
- Changelog Display: Recent changes now visible to users for better transparency.
- New Blog Post: "Best Practices & API Integration" guide added to the blogs section.
- Dark Theme: Added support for dark theme for improved accessibility and user experience.